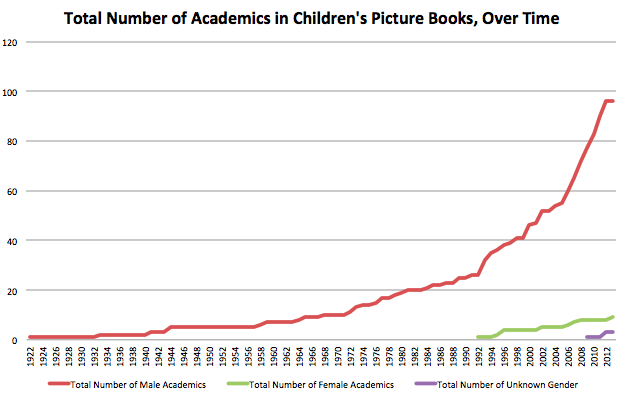
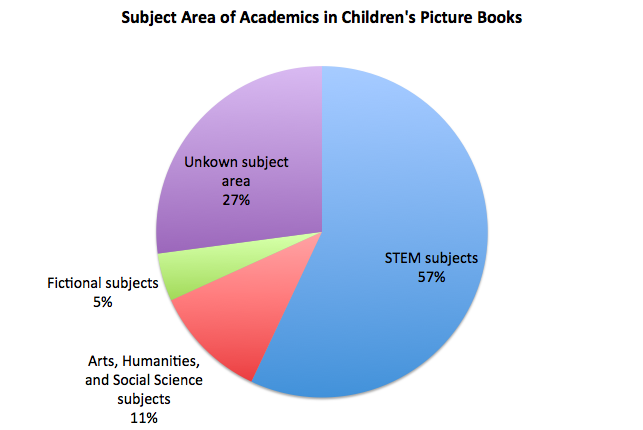
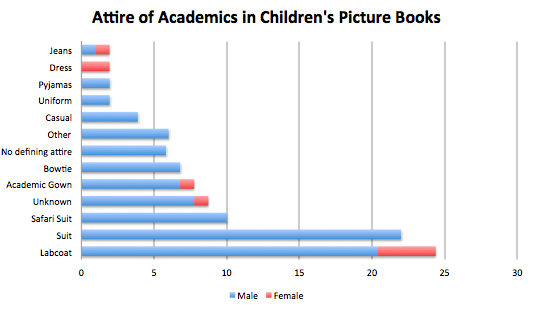
What are the most commonly accessed digitised items from heritage organisations? Even asking the question leads to further understanding about the current digitisation landscape.

Last month, at a meeting at the National Library of Scotland, an interesting fact flew by me. The NLS has hundreds of thousands of digitised items online, so what do you think is the most popular, and most regularly accessed and/or downloaded? (it is difficult to make the distinction regarding accessed or downloaded on most sites.) Is it the original Robert Burns material? The last letter of Mary Queen of Scots? or any of the 86,000 maps held in this, one of the best map collections worldwide? No. It is “A grammar and dictionary of the Malay language : with a preliminary dissertation” by John Crawfurd, published in 1852. This is accessed by hundreds of people every month – mostly from Malaysia, partly because it is featured on many product pages providing definitions of malaysian words – demonstrating the surprising reach and potential in digitising items and then making them freely available online, reaching out to a worldwide audience far beyond the geographical local of the library itself. Wonderful.
This left me pondering… what are the other most downloaded items at major institutions in the UK? So I sent out some feelers, and here are the results, demonstrating both the hidden complexity of the question, and the relationship of digitised heritage content to the current online audience landscape.
At Cambridge University Library, the most accessed collection overall is the Newton Papers, which was the first major digitised collection launched by the Library in 2010, and promoted widely. Within that, there is one particular notebook (which Newton acquired while he was an undergraduate at Trinity College and used from about 1661 to 1665 for his lecture notes) which is the most popular, featuring heavily in the initial promotion of the collection, and also in an In Our Time special series hosted my Melvyn Bragg on Radio 4. But within that notebook there is one page that is accessed more than the others, with most of the traffic coming from Greece. Why? This page was picked up in the Greek press and pointed to on many websites, blogs, newspaper reports, and in social media as evidence that Newton knew Greek. The links that remain still direct thousands of users to view Newton’s jottings from his Greek lessons at the front of the book, showing the fascinating relationship between publicity, social media, linkage, and an item which reflects national pride, to a worldwide audience.
The most downloaded items at Cambridge also reflect the rapidly changing mentions of items on social media: in April 2014, an item downloaded/accessed more than 6000 times was the Breviary of Marie de Saint Pol, which went live this month. Why the sudden notice? On the 3rd of April, one of the Cambridge colleges with thousands of followers posted a link to it on Facebook followed by the Cambridge Digital Library Facebook and Twitter feed on the 4th of April. Retweeted a few times, these few postings led to the thousands of views of the document, demonstrating the growing importance of using social media to tell people about newly mounted digitised content.
Over at Trinity College Library, the most accessed item from their digital collection in general is the Book of Kells, which again was their first major digitised item, heavily promoted in the press, and attracting a level of viewing that is unique due to general tourism and cultural heritage interest. The second most accessed digitised item is the surprise: a book of Lute music by William Ballet, from the 17th Century. There is much discussion of this item, and links to it online, posted by online communities of lute players, and those who blog about lutes worldwide. Interest and demand in at item can therefore be encouraged if interested online communities hear about it, and share with their membership.
A similar tale about the importance of publicity and social media emerges from the British Museum. There are popular items about the Viking exhibition which are linked from their home page at the moment given the current exhibition, but since the 1st January 2014 til now, the most popular item accessed in the digital collection (no, wait, go on, guess…. Rosetta stone? Vindolanda Tablets? …) is the Landscape Alphabet by Joseph Hulmandell (no? me neither). These were discovered and shared on social media by type enthusiasts on twitter in mid February, and promoted by the cool-hunter the Laughing Squid who has almost half a million followers on twitter, which caused a sudden spike (I cant see the British Museum actually tweeting them out themselves on their timeline). However, the initial swell of tens of thousands of hits has since dwindled to nothing, showing the fickleness of attention that comes with the social media stream. In 2013, the most single viewed item at the British Museum was… (go on, guess!)… a lead sling bullet, viewed 42,156 times in total. Why? It was picked up on reddit, due to the sarcastic inscription “some ancient sling bullets excavated from the city of Athens, Greece were inscribed with the word “ΔΕΞΑΙ” (dexai), which translates to “catch!”” which generated a lot of online LOLs (“Halt gentlemen. Do not yet partake of the feast before us, for I must capture the image of it with instagram whereupon I shalt bequeath it to my herald upon Facebook for all to see.” here) and this encouraged – and still encourages – visitors to the British Museum website: some forms of posting on social media generate the long tail of usage more than others.
Things start to get more complicated when various digital asset management systems (DAMS) come into place – often institutions have more than one database of digitised content, from different suppliers, with different licensing restrictions and requirements, and so ascertaining the most viewed single item is not a simple question. Organisations also post and share content in various different places. The National Library of Wales are looking through their DAMS to see which items are the most accessed, but immediately know that the most popular item they hold that has been posted to Flickr (with no known copyright restrictions, contributed to Flickr Commons) is the photograph at the top of this post, Dog with a Pipe in its Mouth, from the P. B. Abery Collection. Again, this is an image which has been mentioned regularly on blogs, social media, and internet chats, as well as being a featured image on the 2013 anniversary of Flickr Commons: the fact that it has no copyright restrictions encourages its reuse – and therefore traffic towards its host institution’s site, if those users point back to it – online.
The libraries at Oxford University, including the Bodleian, have been digitising items for over twenty years, and so it is difficult to say what the most accessed or popular items are, due to the way the systems have been designed, implemented and integrated over the past two decades. Their most downloaded or accessed digitised book, scanned in collaboration with Google, is probably the “History of the Scott Monument, to which is prefixed a biographical sketch of Sir Walter Scott” by James Colston (published 1881) – a freely downloadable version is available from its library record (ignore the resellers offering printed versions generated from this for much cost on amazon and eBay!). As far as images are concerned, the most popular at Oxford are among those listed on Early Manuscripts at Oxford University, partly because many of them have been up continuously for twenty years (legacy data for the history of downloads of specific images are not available, indicating how difficult it is to access long term data about this. Server logs get very big very quickly and so are generally periodically discarded, and it is only recently that reporting facilities such as Google Analytics have allowed a quick and easy overview of the usage of websites). Currently popular digitisation projects at the University of Oxford Libraries are the Polonsky Foundation Digitization Project, and the recently launched digitized First Folio of Shakespeare’s works, but there isn’t sufficient data available from all the digital collections to be able to say one way or the other which is the one most popular project, never mind item. It was also pointed out, though, that you would probably struggle just as much (if not more so) to identify which has been the most requested book in the Bodleian’s collections!
This trend of databases complicating the question continues at the British Library, where their digitisation outputs and projects are made available via multiple platforms and viewers, some managed by the British Library, and others by commercial partners, with some content available for free, other content via subscription, or paying a fee per image. These are only some of the most popular different sites: https://imagesonline.bl.uk, http://www.bl.uk/treasures/treasuresinfull.html, http://www.bl.uk/manuscripts/, www.sounds.bl.uk, https://www.flickr.com/photos/britishlibrary/, http://www.britishnewspaperarchive.co.uk/, http://find.galegroup.com/bncn/, http://gdc.gale.com/products/17th-and-18th-century-burney-collection-newspapers/ and the BL module on http://www.biblioboard.com/libraries.html. In addition, there are BL digitisation partnerships with other content providers, for example http://idp.bl.uk/ and http://eap.bl.uk/. Finding out the most accessed digitised item from within this is tricky (but not impossible – they tell me they are looking into it). The fact that they cannot say immediately demonstrates the complexity of running many large databases of digitised content.
These results, from very different institutions, invite discussions on shallow versus deep engagement with digital collections. Some examples of commonly accessed material are what we would think of as part of the Canon of Digitised Content: Shakespeare, Newton, Medieval Manuscripts. Some examples of commonly accessed material here can be taken as little more than clickbait – LOL! History! – or free reference material – its a free Malaysian Dictionary! Bonus! – but is getting people through the virtual door to digitised collections in this way, and through these items, such a bad thing? Come for the Dog with the pipe in its mouth! stay for the genealogy, then the discussions on palaeographic method! One can also argue that some of the discussion surrounding these objects are exactly what we are trying to encourage – many of the hundreds of comments posted on the Reddit item about the British Museum sling shot bullet, although hilarious, show consideration of what it would mean to be human in the time of Ancient Greece, and relate their societal response to ours. Isn’t that the starting place (and in some cases, the ending place) of engagement with primary historical evidence?
Asking to see Digitisation’s most wanted opens up wider questions of public engagement, the impact of social networks on internet traffic to digitised collections (from highlights posted by the institution, to those identified and shared by others outside it, often quite unexpectedly), and the role of making images of primary historical sources open for others to discover, use and share. We also become aware of the complex and intertwined database systems which are in place in many large organisations undertaking digitisation and delivering digitised items to users, and the difficulties in reporting on individual items (be they physical or digital!) as a result. Digitisation’s most wanted is also a rapidly moving target, dependent on publicity, and changing interest and focus over time: social media can encourage large swings and changes in popular items very quickly. The act of posing this question has led to an interesting discussion on how we think about use of digitised content, and how we can build up evidence about usage. (I’d also like to thank the organisations listed above for responding to my query so promptly!)
Have you, or any organisation you work with, been affected by the discussion in this blog post? Do you have any evidence you can contribute to the investigation? Your help is needed to catch digitisation’s most wanted. Please do post your comments about your experiences below (comments are moderated so may take a few hours to appear), or email m dot terras at ucl.ac.uk for them to be integrated here. The internet is a place of busy traffic. Someone must have seen them…
Update 15/05/14: The British Library’s Endangered Archives’ most popular item is the St Helena Banns of Marriage, an item commonly pointed to on genealogy websites such as this and this.
Update 16/05/14:
-The National Library of Australia have a discussion of their 25 most viewed digitised newspapers, and why, here.
– The International Dunhuang Project at the British Library tell me that a redevelopment of their database and website is underway to improve reporting for them, their partners and users.
– Glasgow University Library Special Collections tell me that their most popular item is the Curious Case of Mary Toft, from 1726, who supposedly gave birth to a litter of rabbits. This was featured as a book of the month in 2009, but picked up by the social media site Mental Floss in January 2014, with that page being shared on facebook more than 4000 times, and garnering 30,000 hits in one day alone, and has since been posted on various other social media platforms, including Reddit. Glasgow also say that there is a difficulty in measuring access counts as the content is held on various different servers, and it can be difficult to interpret Google Analytics in this case. They also point out that, from their perspective, there is a lack of benchmarks to compare usage of their items to that of other special collections.
– The National Archives tell me they point to the popular items as part of their navigation and as a result, these “most popular items” remain the most popular, in a virtuous circle. A very popular item at the moment is the The Security Service: Personal (PF Series) Files KV2 which hosts the records of spies such as Mata Hari. These were embargoed until Thursday 10 April 2014, then launched with an accompanying press release, which garnered significant press coverage worldwide, driving traffic to the site. The only frequently accessed item which is not in these lists is the muster roll of HMS Victory for the Battle of Trafalgar, which is commonly referred to in military and naval history websites (although interestingly few people link through directly to the page where it can be downloaded from, so those who read about it must come to TNA’s website and search themselves).
Update 19/05/14
– The Estonian Folklore Archives at the Estonian Literary Museum tell me that their most popular item is a leaflet from 1937 on how to preserve sealskins, although I can see no other webpages pointing to this item (perhaps because my Estonian search skills are weak!).
– UCLA Digital Library tell me their most viewed item is a Lyrical Map of the Concept of Los Angeles, a 23-foot long hand-drawn and hand-lettered map of Los Angeles, using the words and images of dozens of L.A. authors, which was on display in a museum in 2011, and was featured widely on blogs both at the time of the exhibit and since, which points people to the digital version now the display is no longer live in the museum space. Another popular item is the complete set of the 1582 Corpus Juris Canonici, the “Body of Canon Law,” particularly the table of contents, which is commonly linked to from those interested in Canon Law, such as this, thus driving subject specialists to the site.
– The History of Computing in Learning and Education Virtual Museum tells me the most viewed items are the writing competition and Historic Newsletters from the People’s Computer Company.
– A Hack day carried out at the Zurich Hackathon 2014 looked at image analytics from the US National Archives and Record Administrations contributions to flickr commons, looking at 200 million hits in a 3 month period and identifying the most common images: a description of that hack is here, which also gives examples of the most commonly looked at images. “There is a spike on March 24. Further analysis shows that the biggest referral on that day is Dorothy Height. Turns out this lady was featured on a Google Doodle on that day.” Popular subjects (and referrer pages, generally from Wikipedia) were John F. Kennedy, World War II, Japanese American Internment, Vietnam War. A full list is available on the project page. This shows the importance of institutions linking their content from Wikipedia, and what can happen if you are featured by Google.
– There is also a useful tool in BaGLAMA which shows view counts for pages using Commons images in GLAM-related category trees.
Update 20/05/14
– The Bodleian also make the very good point that “With most browsers now defaulting to ‘do not track’ combined with the EU cookies legislation it is difficult to find any sort of data that one can ‘stand behind’ these days.”
– The Jüdischen Museums Berlin‘s most accessed items are the Sammeldatensatz: Orden, Ehrenzeichen und Embleme von Julius Fliess (1876-1955), but they say that most accesses come from searches for “jewish emblems”, and so there is a need to add emblem as synonym for symbol to thesaurus, to help users find what they are looking for. In this way, looking at search terms can help develop user paths through the system so they can find what they actually want.
– The University of Iowa Digital Libraries say that based on google analytics for the last year, the most popular item is a dada book, and the most popular collection is Iowa Maps, but the access numbers for different objects in the database themselves are hard to count, and they’ll get back to me on that. Based on recent web searches reported from the web master, a surprisingly high number of people find them via searches for Peter Rabbit: the digital book of which is linked through to their site from the Wikipedia page and various other websites featuring Peter Rabbit.
– The National Library of Wales tell me the most popular article on http://welshnewspapers.llgc.org.uk is a 1916 Cambria Daily Leader advert for ‘blouses’ and ‘hosiery’. To find out more about why may take some digging, though!
– Hamlet Depot and Museums tell me that their most popular items are genealogical records, including railroad employees lists, and seniority records, and also historic pictures.
Update 22/05/14
– The New Zealand Electronic Text Collection tell me that reference works are their most used, including A Grammar and Dictionary of the Samoan Language, with English and Samoan vocabulary (which is linked to from thousands of different sources about New Zealand culture, and discussions on translation), New Zealand in the First World War (which is linked to from various history and genealogy sites) and The Official History of New Zealand in the Second World War (which is also popularly linked to online, including in reminiscing personal postings from soldiers who served, talking about the war on social media).
– The University of Otago Library provided me with a very detailed overview of the issues they face (thanks!). They are in the process of developing a repository to manage all of their digital collections that they want to curate, and the pilot will be live by November, but for the moment, they have a variety of different sites on which you can see digitised material, showing again the complex relationship of databases and content which many institutions have. For example, they have OUR Heritage which is a window across some collections. Some records are pulled from OUR Heritage and displayed via Special Collections Online Exhibitions. There also is Hocken Collections who had their reader access collection digitised and made available online. They track this via Google Analytics, and also watching their own server stats: and these do not in any way match up. Google does not capture when someone goes directly to a file, so Analytics reports just a fraction of the over a million hits in the past year that they can track on their server. They digitise on request, and respond to community demand, and are trying to prioritise the digitisation process. From Google Analytics, the most heavily used collections are the History of the University and Botanical charts (which belong to the Department of Botany at Otago and some are still used in the Labs. They digitised these, provided a copy for their use and deposited the originals in Hocken Collections.) The most popular items are “Key plan to Mr G.B. Shaw’s picture of Dunedin in 1851” which is mentioned on various genealogical sites online: a Painting “Sangro, a rosary of olive trees, landscape of windswept manuka.” which appears linked from some other major federated collections online and a printed map of Rome “Mappa della campagna Romana del 1547” which is a commonly consulted map (there are various copies of it in libraries worldwide) so those searching online to see it must find the freely available copy here.