An (award winning!) regularly updated concluded blog post in which I document trying to get a license to reuse an item for which no copyright information exists, under the UK Government’s new legal framework.
Diary Entry 1: Weds 29th October, 1.16am UK time
Well, today’s the day! Wednesday 29th October, the day the UK law changes to allow licenses to be granted for “orphan works” – items whose copyright owners cannot be located. This is a thorny problem – as a recent government publication explains:
If an individual wants to use a copyright work they must, with a few exceptions, seek the permission of the creator or right holder. If the right holder – or perhaps one of a number of right holders – cannot be found, the work cannot lawfully be used. This situation benefits neither the right holder, who may miss opportunities for licensing, nor potential users of those works. This is not a situation peculiar to the UK; other countries face the same issues [source].
A new framework was announced as part of the Enterprise and Regulatory Reform Act 2013, and has been implemented after a consultation process earlier in 2014. The UK government also introduced regulations to ensure that they comply with the EU Directive on Orphan Works. This new scheme will be administered by the UK’s Intellectual Property Office.
In my previous blog post I introduced a lovely orphan work, from the mid 1960s: a “lantern” interval slide tempting patrons to buy an ice lolly, used at the Odeon Cinema, Eglinton Toll, Glasgow.
The image is used here with permission from the Scottish Screen Archive, National Library of Scotland. It’s part of a collection of Lantern Slides, with no individual collections record. It has a small identifying note to say it was made by Morgans Slides Ltd, which is no longer trading. The Odeon cinema were contacted, but their records dont go that far back for design so they cannot prove they own copyright, but they gave me permission to use it if they do, with the caveat that a copyright owner, whom they cannot speak for, may come forward at some future date. It’s an orphan.
I want to adopt it, so I can use it widely, but also, to investigate how easy? hard? costly? problematic? easy? it is to get a license for orphan works under this new scheme.
So let’s go! This blog post will expand over time as I update on the process. I have all the data I can get on the item gathered, and am ready to roll. I contacted the IPO last week via email, and they promise that “all the relevant information on how to apply for a license and the due diligence needed will appear on the website on Wednesday morning”. There’s nothing up there yet (I’m on Australian time writing this, in Melbourne, and its only just past midnight in the UK)… but will check back later, come UK business hours.
Diary Entry 2: Weds 29th October, 11am UK time
It’s online! Here we have the process and the system of how to apply for a license for an orphan work. It’s an online form – I’ll get cracking with it…
Diary Entry 3: Weds 5th November
Its taken me a week to update this – not because I’m not interested, but because I’m over in Australia just now on a lecture tour, and its been a jolly whirlwind of lectures, lunches, masterclasses, flights, trains, dinners, and kangaroo spotting. Excuses excuses. I’m now in a hotel room in Sydney with a few hours spare of an evening and an actual internet connection: lets get to it.
The first thing to report is that the IPO read this nascent blogpost and contacted me! The Head of Copyright Delivery, from the Intellectual Property Office, thought my blog was interesting, and we’ve already exchanged an email or two: they are interested in the needs of our sector, and want to assist in this. Isn’t that interesting (and slightly scary – that’s social media for you) – and I assured them that I wasn’t doing this out of “lets see what is wrong with the process” but in the spirit of genuine exploration. The process is clearly flagged as in Beta, so lets all proceed in manner of mutual respect, and give some feedback as we go. I’m happy to be a guinea pig. (I’ll flag up recommendations to the IPO with a bold IPO: for easy scanning).
The process itself seems relatively straightforward (check list from the IPO website):
- check that the work you want to copy is still in copyright because if it isn’t, you don’t need a licence to use it
- check whether the use falls within one of the copyright exceptions
- read the guidanceon orphan works and take this short questionnaire to find out if you are eligible to use an orphan work under the EU Directive
- carry out a diligent search for right holders in accordance with IPO published guidance
- complete the diligent search checklist(s) and convert these to one PDF document to upload as part of the application process
Then, work out what license you want. So lets go through this check list, to get that first phase out of the way.
1. Check that the work you want to copy is still in copyright because if it isn’t, you don’t need a licence to use it.
TICK! we have an orphan item right here.
2. Check whether the use falls within one of the copyright exceptions
UNTICK! exceptions are for Non-commercial research and private study; Text and data mining for non-commercial research; Criticism, review and reporting current events; Teaching; Helping disabled people; Time-shifting (eh? Dr Who a go-go); Personal copying for private use; Parody, caricature and pastiche; Certain permitted uses of orphan works (which allows the GLAM sector to digitise orphan works and make them available online); Sufficient acknowledgment, and Fair Dealing.
Now, I’m no lawyer, but none of these are me: what do I want to do? I want to take an orphan work, and make some fabric with it using it as the basis for a pattern, and perhaps make a few items of things, which I might want to sell on etsy, or put the pattern up on spoonflower, etc. Yes, there is a teaching and research element to this, but by the same token, the teaching and research is in the fact of making it available, and chasing through the process. It’s not commercial a la huge superstores, but its certainly not uncommercial, even though the chance of making a profit is slim. I’d say that there were no exceptions to copyright for me in this case, so we (un)tick the item, and proceed to the next in the checklist.
3. Read the guidanceon orphan works and take this short questionnaire to find out if you are eligible to use an orphan work under the EU Directive.
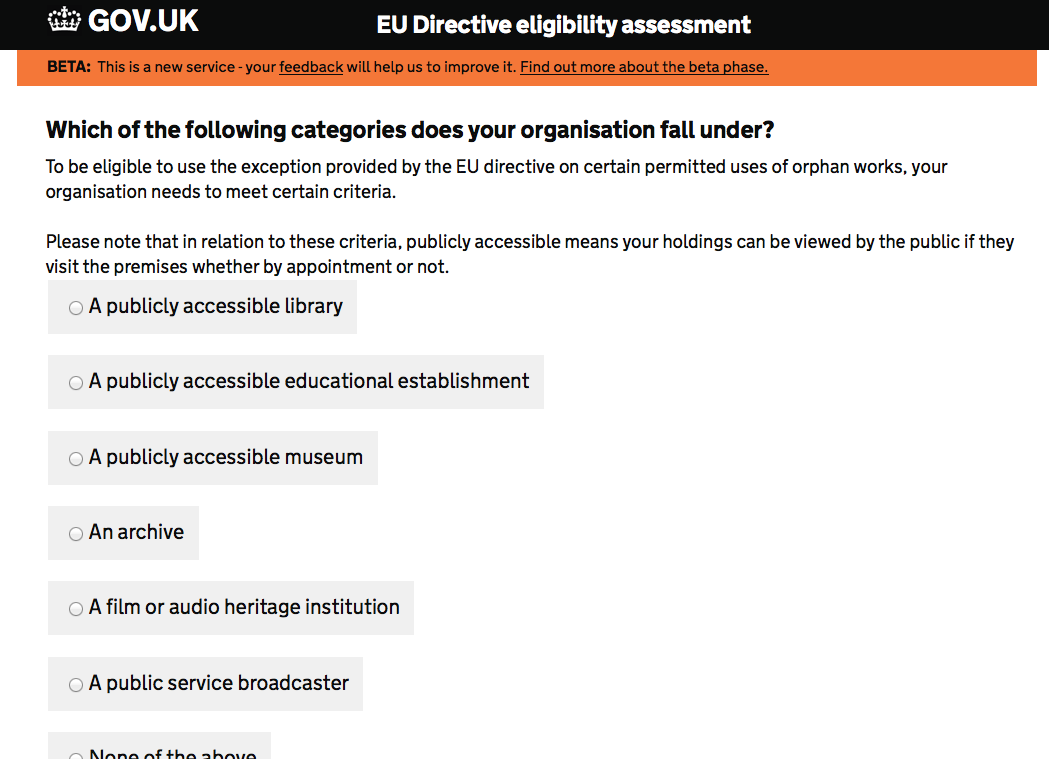
Read it (interesting read). The checklist for the EU Directive the first thing where I go… wait a minute, Gov. See screenshot.
Problem number 1: I’m not an organisation. I’m just a person. If I wanted to start trading and selling this stuff, I’d be starting off as a sole trader, which is still not really an organisation. So I already dont know if I’ve met this check list or not, given I’ve been asked what categories my organisation falls under (so, recommendation 1: IPO I’d be putting in some thing about being an individual person on that screen). I’m very much “none of the above” so lets tick that, which gets you to:
I’m not exempt, as I thought, although who knows because of the organisation thing… so lets crack on with the licensing scheme.
4. Carry out a diligent search for right holders in accordance with IPO published guidance
TICK! I have all my info here, good to go!
5. Complete the diligent search checklist(s) and convert these to one PDF document to upload as part of the application process.
The form is a bit of a funny beast. First, you have to select from a list of different forms, choosing one which may apply to you. As ever, its really hard to make up a list that covers everything, so it took me a bit to decide that I should file my request under “still visual art” which is the closest there is to it. Then you get to filling out the form, which mostly a list of places you should check to see whether the item is listed or found – first page screenshot:

The list of places to check goes on and on: British Society of Underwater Photographers (BSUP), Bureau of Freelance Photographers (BFP), Chartered Institute of Journalists (CIOJ), Editorial Photographers UK (EPUK), Master Photographers Association (MPA)… I make it 55 different places you have to check to claim that it is an orphan work, which is fine: you want to be diligent about this (the clue is in the title). But, recommendation 2: IPO it would really help if you said exactly where you wanted people to check (giving URLs would help a lot) and how – for example, “water mark search or image recognition software” is quite a broad church. Another thing recommendation 3: IPO is that a lot of the places are societies, and I’m not sure what they thought you could do there, or what they have that is relevant. For example, if you go to the Professional Cartoonist’s Association website, you can browse portfolios, but I cant seem to search for “lolly time”, and its much more a membership organisation than a repository for content. So I’m not sure what I’m being asked to check: that I had a quick look at the website? that there was nothing of relevance because they dont have a repository? that I was supposed to email them and ask? Guidance on that would be super useful.
But I worked though the list diligently – and I know how difficult it must have been to put together that list of things, as one size wont fit all, and I tried not to get frustrated by demonstrating why Its Lolly Time isnt probably going to be relevant to the Society of Wedding and Portrait Photographers, but it is what it is. MS word was probably the easiest way to go, but it would be nice recommendation 4: IPO if there could have been a slightly more interactive way to choose which evidence you want to present (where do I attach my emails from the National Library of Scotland, or the Odeon, for example?)
Now on to choosing a license that you are applying for! And it is here that the fun starts! Because that’s where you get to play with the cost calculator to buy the license.
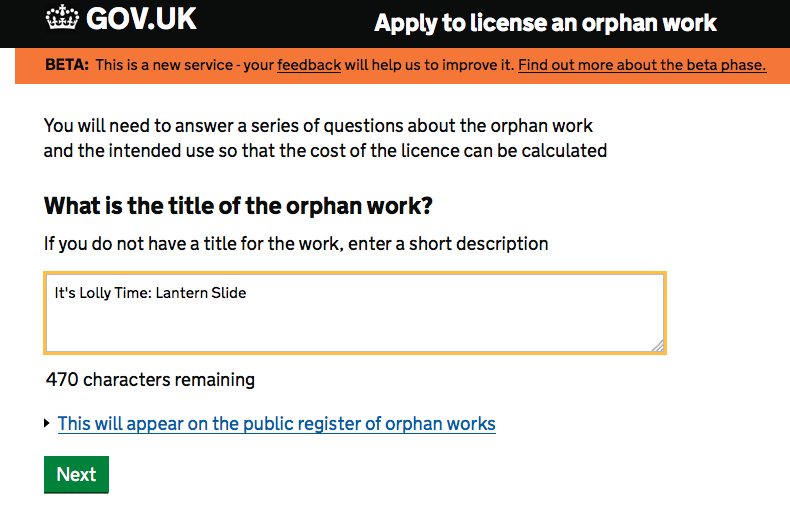
First, you name the item, and choose carefully my friends! as that will go in the register:
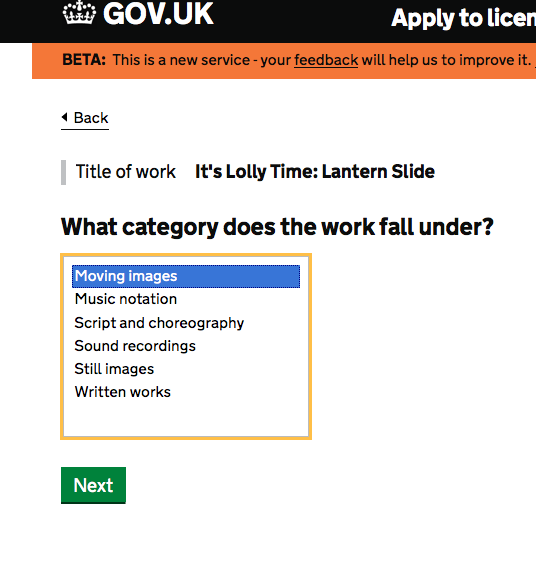
Then you choose a category:
Again, its hard to come up with these categories, and “my” objet doesnt really fit anything, but lets go with still image (recommendation 5: IPO you may want to expand on that list a little?) And then you choose subcategory:
Umm… I dont know. Illustration? Maybe?
And then comes the killer question… DA DA DAAAA!
Well. I want to get a license that means I can put something up on etsy or spoonflower, so technically is that commercial? I dont know (IPO: I’ll be emailing you about this!). Their further information would seem to think so:
So even selling one thing = a commercial license needed. Ok. Lets got the nuclear option, and choose monetary compensation! For…
Let’s go with retailing and merchandising? And with checking that, I know that one does not simply walk into Mordor. As individuals who are interested in making one or two things are suddenly being lumped into the same categories as large chains that want to sell tens of thousands of items…
There’s some more granularity and some more drop down menus – what is the exact use of this work? erm… On apparel? that’s scarves, right? and for spoonflower? (further gulp. We are not in Kansas now, Toto). There is a prompt to contact the IPO if the exact use is not listed, and I think we need to come back to this idea of individuals and small businesses using content, versus massive clothes manufacturers because once you see the costs, in a minute…
But first, I have to choose how much surface the item will cover?
IPO recommendation 6: I’d suggest this is a nonsensical list. Why? Well, repeating patterns are pretty common. How do they relate? My scarf is bigger than a “page”. So what does this mean? And what is a page? A4? A3? A0? you might want to revisit this. My orphan image will cover as much fabric as you can print out, as its repeated. But lets go the nuclear option, and tick “more than a full page” for a commercial license, for apparel!
You are then asked to choose how many things you are going to make to sell. I’m thinking of making two or three, just to test the waters (starting up as a sole trader, remember!) but the minimum item load you can make, in the licensing structure, is…. 5000!
IPO recommendation 7: its clear that these structures are geared towards large corporations, rather than individuals or sole traders. I’d revisit this: you want to help bootstrap creative making, not treat everyone like Walmart? But I’ll click 5000 or less for now.
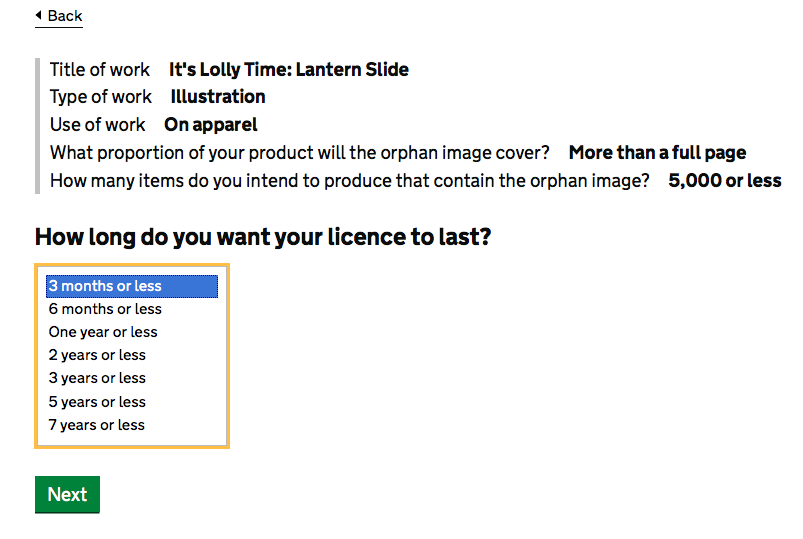
Then you have to choose how long the license is going to last for.
Shortest is 3 months, longest is 7 years… hmmm. Well, selling these two or three items is going to pay for my early retirement, so lets go for 7 years (IPO recommendation 8: it would be good to know if once you have licensed an item, noone else can? Or if multiple people can license the same thing? just a thought)
So here we are. A 7 years license to use an image on a repeating pattern for apparel that I can sell, less than 5000 items. And the cost comes to…. drumroll!!!!!
Did your eyes go as big as mine did when that figure popped out?
Now, its clear that I’ve stumbled into the commercial sector line here, and this is probably a fine amount for an image license if you are a major clothing retailer. But there is no way that I can stump up over £2.5k to allow me to put some scarves on etsy, or fabric up on spoonflower. I need to email the IPO and ask about this, which I will do next, and report back, but before I do … I wonder who is benefiting from these license costs? Where does the money go to? I’ll ask the IPO about that and update the blog with the info they supply.
Of course, we could go back to the start of the process, and I could decide that I’d make things and donate any profits back to the NLS, in which case I would check the no commercial gain box. The process (and costs) are then significantly reduced:
A mere ten pence for non commercial use (hurrah!). But I’m not sure if what I want to do is covered under this list. Perhaps “personal use” – it could be argued that I am just making the digital files available for people via spoonflower (or I could make the digital files available to print up a scarf, and tell people where to go and get one if they do), but my dreams of etsy stardom reusing digitised content have been dashed.
It’s clear that I need to talk to the IPO about this and ask the best way to proceed – and I’m aware that I started a very public conversation right from the get go – but it does seem to me that the licensing structure, as is stands in Beta, allows reuse for freebies but doesnt really allow people to make products out of orphan material, unless they are for personal use only – and to be fair, I got that license from the NLS in the first place, so I’m not sure what is to be gained here, appart from the fact I could now share the source files of the item I made for personal use with everyone else. The licensing costs do hamper anyone wanting to start making and selling at a cottage industry scale, which is the majority of the online marketplace over at places like etsy, and probably a major source of reuse for this content: it should be opened up for everyone to use? Or am I being naive or utopian?
So I’ll take this back to the IPO, and ask them to think about how this helps or hinders uptake of this material so you can actually do something with it if you are not a corporation, and report back. I’ll also ask for the table of licensing costs from the IPO, which must exist somewhere, so that I dont have to spend ages with the online tool manually drawing that up myself. The online tool is pretty straightforward (save the baffling question about pages?) and usable, given the complexity of the range of uses people must be asking them for, and its great that it went up on the day the legislation changed.
The orphan works scheme – especially the 10p non-commercial license – is fantastic for the heritage sector as it does clear up a lot of issues with reusing content for not for profit usage, but I was hoping I could do something more… I’ll be right back when I have more to report, travel and poor internet access notwithstanding.
Diary Entry 4: Friday 28th November
The delay to updating is all my fault, due to catching up on life and work (and sleep) upon my return from Australia. The IPO were really very quick to respond to my query, and it has sat in my inbox for a couple of weeks (sorry for being so tardy IPO, and thanks for being so speedy yourself).
Here is what I asked, and how they responded. I quote directly from an email to me from the Head of Copyright Delivery at the IPO.
1. I asked: Where does the money from the licenses go?
They said:
The application fee covers the cost of processing your application. The licence fee (minus the VAT of course, as that will have been transferred over to HM Treasury) is held in case the right holder for the work comes forward. They have a period of 8 years to do so, and if we are satisfied that they are the right holder, we will pay out the licence fee. If they do not come forward in 8 years, we can use the money to pay for the set up of the licensing scheme, and also for ‘social, cultural and educational activities’ (regulation 14 of The Copyright and Rights in Performances (Licensing of Orphan Works) Regulations 2014 – http://www.legislation.gov.uk/uksi/2014/2863/contents/made).
2. I asked: Even if you only sell one or two things, do you need a commercial license?
They said:
As you set out in your blog, if there is any money changing hands for the use you are making, it counts as commercial. If you are going to put the pattern on Etsy or similar for free, it would be non-commercial.
3. I asked: Can I get a copy of all the licensing costs?
They said:
Our pricing structure runs to literally thousands of possibilities for licences, so it is not possible to send you all costs for commercial content – it really depends on the type of orphan work and the use you want to put it to.
4. I asked: How were the licensing costs worked out? Were commercial costs used as a model?
They said:
We undertook a detailed analysis of prices for non-orphan works, taking into consideration both the type of work and the use. This used information from a wide range of sources, both commercial and non-commercial providers. We had always committed to ensuring that orphan works do not distort the market unduly against non-orphan works, which provides a certain level of reassurance for right holders and licensors in the market.
5. I asked: Is a license exclusive? So if you pay all that money, could someone else also get a license?
They said:
The licence is non-exclusive, so someone else could apply to use the work for a similar or different use at the same time as you using it. This is because we have no way of knowing whether the right holder would negotiate an exclusive licence or not.
They also directed me (and you, dear readers!) to the scheme overview guidance on gov.uk: https://www.gov.uk/government/publications/orphan-works-overview-for-applicants.
This makes it much clearer for me, and I can see the reasoning behind such decisions, although I’m going to ask them to offer a significantly smaller run of items (the minimum you can get a license for is 5000 at the moment, which really does stop small businesses experimenting: a minimum license of 20? items, with a license fee reduced in ratio to the number of items would bring the license costs way down, whilst allowing our kitchen-table makers to use orphan works in items offered for sale at a small scale). I’ll ask them, and brb, honest.
I also have an issue about orphan works being offered for sale at the same licensing rates as commercially available art is… although I can see why you dont want to flood the market with low cost design materials and put today’s beleaguered designers out of work (its a tough enough gig out there at the moment). However, this still means that there will be so much really fab cultural and heritage material locked up in institutions that people cant afford to use. Harrumph.
I also consider that there must be a model that generates all the costs: its not like computers spit out all this stuff themselves without any human input. I do know a little about that, in my line of work. So I’ll ask again about getting hold of the underlying model that generates costs.
And what am I going to do, myself? Well, I’ll wait til I get a response about lowering the number of licenses available, and if they do, I’ll buy a commercial license for 20 units, and get my make on. But if they wont, all I can do is apply for the non-commercial license, and make source files available for others to use in a not for profit manner. There’s very little in that for me (for the price of £20.10, including processing fee) but I feel I should see this process right through to the end, even if it isnt the magic, transformative process we had all hoped for, for the cultural and heritage world.
Diary Entry 5: Monday 5th January 2015
It’s worth pausing for a moment here, to think about what the alternative to chasing such a license are. Of course, there were a lot of changes to the law in October last year regarding copyright and orphan works, not just the orphan works scheme, but exceptions to the scheme. Just before Xmas I had the delight of taking one of Naomi Korn‘s one day courses on Digital Copyright. She was keen to point that for many institutions these exceptions may be more than adequate for their needs, and compares the exceptions to the licenses in a table below, which I’ve been given permission to reuse from a forthcoming piece by Korn called “The Orphan Works Dilemma”.

In many cases, provided due diligence is undertaken (and there’s a guide from the UK government on how to do that) then reusing items under the Orphan Works Exception is preferable, easier, and more cost effective than pursuing a license via the orphan works scheme. Its therefore worth exploring this option first, before thinking that a license is necessary for every reuse case of an orphan work.
For my use case – small run commercial printing, by an individual – the exception doesn’t count, so its not a route that is open to me for this particular case. But for many libraries, archives and museums, wishing to display orphan works, or use them in a non-commercial way, the orphan works exceptions are more practical than trying to obtain licenses.
Diary Entry 6: Tuesday 6th January 2015
I have a response in from the IPO, and I think this is as much as we are going to get pursuing this. I’m copying it here, as it is self explanatory:
1. Minimal commercial licences
You asked for a licence for 20 items or less, rather than the 5000 items which is the minimum for using a still image. This is something we will consider going forward, which is why we have a contact form in the application process to allow people to say that their use is not listed. I obviously cannot guarantee that we will offer it, as it depends on us getting sufficient evidence of its need. Do you have any evidence of licensing which allows such small numbers? We would be able to take that into account in making a decision.
2. Fee calculations and sources
You asked about the underlying mathematical model for the fee calculations. I am afraid we are not in a position to share this with you. As I have mentioned before, we have used publicly available licence information which we researched and averaged (commercial and non-commercial). We then took into account relevant factors like the fact that we only offer up to 7 years for the licence whereas non-orphan licences might be available in perpetuity or for other lengths, non-exclusivity versus exclusivity and territoriality. As I said before, this means we do not have precisely the same prices as Gettys, for example, although they were one of the sources of information because they have publicly available information.
3. Unclaimed licence fees
After the 8 years, as you know the unclaimed fees are first use to defray the setting up and running costs of the scheme. Then any excess will be used at the discretion of the Secretary of State for social, cultural and educational activities. This could be a wide variety of activities, which might include cultural heritage research, digitisation projects or benevolent projects for right holders. It is some time in the future, so it is difficult to say what might qualify under any given Secretary of State’s opinion, but I hope that gives you a better sense of what might be included.
Interesting. I think (1) is rather the wrong way to think about it: they have compared commercial licensing costs for stock photography with the licensing of orphan works that are mostly of historical importance, within institutional contexts… It is rather like applying rules for apples to those for oranges. There is an opportunity here to do something different that will help the use of content in the library and archive sector, not just to ape what is happening in industry (with a licensing structure that is set up to maximize profits and minimize time wasting experimentation). The model really doesnt apply here. But that said, the lowest licensing number that the IPO offers is for 5000 items, but a quick look at the main stock photography licensing sites shows that iStockPhoto licenses a maximum of 2000 items of apparel created with an image. If I understand it correctly, BigStock’s license allows you to print on apparel with no limit, with the cost of each image being significantly less than the quote given here.
You could spend weeks working out the licensing structures for stock photography, which are often not comparable across websites, and I dont think that the costing structure here has really been worked out in such a way to take the needs of the library and archive sector into account. I understand the need to balance the needs of commercial artists, photographers, and illustrators, but I think concern for them has outweighed the needs of the cultural and heritage sector. Given the costs, and the restrictions, if I were in an institutional context such as a library or archive, I wouldnt advocate going down this licensing route at all, but I would try and do what you could do within the exceptions, as detailed above. The orphan works licensing scheme is good in theory, but in practice it seems overly concerned with the models for commercial stock photography, and not at all concerned with the needs of the gallery, library, archive and museum sector.
Regarding (2): should I pay an RA to sit for a day or two and work out all the licensing fees? We can then retrospectively calculate the model they use. Sounds like fun? Is anyone interested in that bar me? Let me know and we’ll crack on. It may be, though, that the sector has already accepted that these costs simply arent bearable (and you try and license 300 different items, individually, even for non commercial reuse – it would take weeks, and cost ££££.)
I think (3) sound fair – 8 years is at least two governments away, so planning ahead for the state of culture and libraries and museums is like chucking darts blindfolded, anyway. But remind me in 8 years to file a FOI request asking about income and revenue from this scheme – if FOI requests still exist then ho ho ho! (hollow laughter).
So that brings me to the end of my quest, I think. I’ll continue to engage with the IPO about the licensing number question, and fill you in if there are any changes, but its clear that at the moment, as it stands, the scheme excludes people like me: sole traders, wanting to use orphan works in small print runs. And the scheme is too unwieldy, time consuming, and costly, to allow any more than the odd item to be licensed: those wanting a non-commercial license are better trying to look at the exceptions, first.
What shall I do re Lolly Time? I want to share decent images of it, and its free standing artwork, so its not covered by the exceptions. So I’ll file the paperwork for getting a non-commercial license to use this, so I can share the big files of the image online legally, just to wrap this up, and to see that process through. Should anyone take the image once its put online and do anything with it, well, I cant stop them. But you shouldnt go near Etsy with this one to sell…
Diary Entry: 14th March 2015
So where is the license? I’ve tried to get a non commercial license, I really have. I spend 15 minutes carefully filling in all the details to the online system, then I fail at the last hurdle, as it wont let me upload the due diligence form. I’ve tried different browsers, but no. I cant save that 15 minutes of data entry, and need to start again every time. It seems like not only the process is broken, but the online tool. I have emailed the IPO about it, but I think I’m done. I tried, I really did.
I keep getting an error message asking me to upload a pdf file – when I have tried to upload a pdf file.
What has the take up been across the sector, given the licensing scheme has been running for the past 4 months? In total there have been 228 licenses issued altogether to date, with 200 of those from one museum alone (Museum of the Order of St John) and a further thirteen to the Rawk Agency (“one of the UK’s leading providers of boutique and marketing events“).
According to the “In from the Cold” Jisc report on Orphan Works, “across UK museums and galleries, the number of Orphan Works can conservatively be estimated at 25 million, although this figure is likely to be much higher” [link]. The Orphan Works licensing scheme is not being used to make these available in any numbers worth considering.
Addendum, 31/03/15.
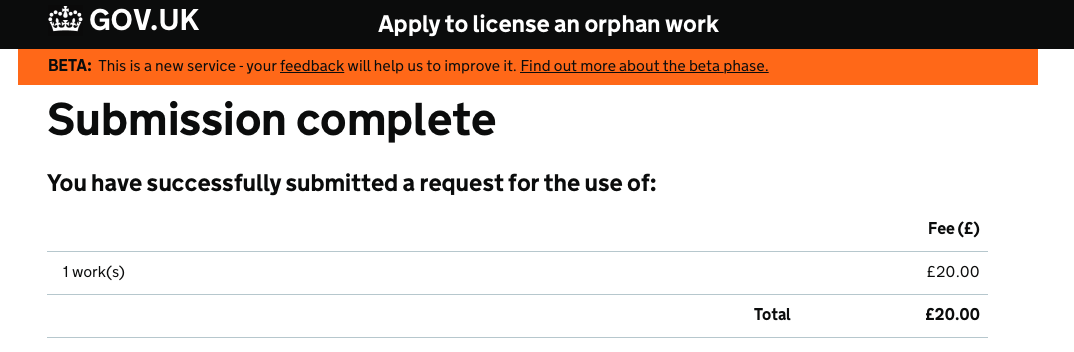
I couldnt let this one lie, could I? It took a chat to the IPO, 3 different browsers, and me tinkering up the back of class while invigilating an exam over a 3 hour period, and look what I just did! I’ll update here with further information, once a license is granted. Victory of sorts, but I still maintain it shouldnt be this hard...
And finally, in April 2015, I got the license. THE END. Now what?
This blog post was nominated for, and won, the “Best Exploration of DH Failure” category in the Digital Humanities Awards 2014 following public voting. Thanks!
Addendum, 18/09/15.
This just in from the Orphan Works Licensing Team at the IPO:
We have been considering the issue, particularly in relation to the
use of an image on apparel, and have looked at the publicly accessible
pricing information available. This has allowed us to introduce new,
lower quantity amounts of 500, 1000 and 2,500 for orphan works
licences – you will be able to check these on the application system.
However, licence fees for the very small quantities you were
suggesting are not universally available, which has meant that it has
been difficult for us to source data for comparison. Where we have
come across pricing information relating to certain lower quantities,
we have added this to the online application system.
W00t. I can haz impact? 🙂 I think this is a move in the right direction (but I’d still prefer to have an even smaller license of 50 or so for those kitchen-table-makers, like me). Great that they are licensing, though!