
In October 2011 I began a project to make all of my 26 articles published in refereed journals available via UCL’s Open Access Repository – “Discovery“. I decided that as well as putting them in the institutional repository, I would write a blog post about each research project, and tweet the papers for download. Would this affect how much my research was read, known, discussed, distributed?
I wrote about the stories behind the research papers – the stuff that doesn’t make it into the official writeup. From becoming so immersed in developing 3D that you start walking into things in real life, to nearly barfing over the front row of an audience’s shoes whilst giving a keynote, to passive aggressive notes from an archaeological dig that take on a digital life of their own, I gave a run down, in roughly reverse chronological order, of the 12 or so projects I’ve been involved in over the past decade that resulted in published journal papers. Along the way, I wrote a little bit about the difficulties getting stuff up there on the institutional repository in the first place, but the thing that really flew was my post on what happens when you blog and tweet a journal paper: showing (proving?) the link between blogging and tweeting and the fact that people will download your research if you tell them about it.
So what are my conclusions about this whole experiment?
Some rough stats, first of all. Most of my papers, before I blogged and tweeted them, had one to two downloads, even if they had been in the repository for months (or years, in some cases). Upon blogging and tweeting, within 24 hours, there were on average seventy downloads of my papers. Seventy. Now, this might not be internet meme status, but that’s a huge leap in interest. Most of the downloads followed the trajectory I described with the downloads to Digital Curiosities, in that there would be a peak of interest, then a long tail after. I believe that the first spike of interest from people clicking the link that flies by them on twitter (which was sometimes retweeted) is then replaced by a gradual trickle of visitors from postings on other blogs, and the fact that the very blog posts about the papers make them more findable when the subject is googled. People read the blog posts – I have about 2000 visitors here a month, 70% new, with an average time on the site of 1 minute and 5 seconds. You come here and tend to read what I have written (thanks!) and seem to be clicking and downloading my research papers.
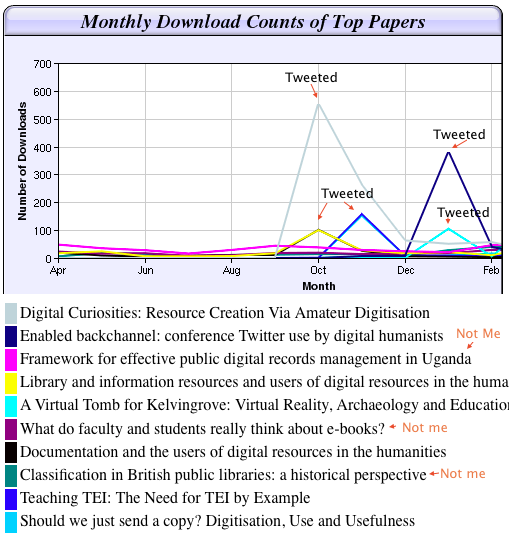
The image above shows the top ten papers downloaded from my entire department over the last year. There were a total of 6172 downloads from our department (UCL Department of Information Studies is one of the leading iSchools in the UK). Look at the spikes. That’s where I blog and tweet about my research. I’m not the only person producing research in my department (I think there are 18 current members of staff and a further 20 or so who have moved on but still have items in the institutional repository, but I’m the only person who has gone the whole hog on promoting their research like this). You will see that 7 out of 10 of the most downloaded papers from my Department in the last calendar year have me in the author list. As a clue, I dont know anything about Uganda, e-books, or classification in public libraries. 27 out of the top 50 downloads in our department in the last calendar year feature me (as a rough guide, I get about 1/3 of the entire downloads for my department). My stuff isn’t better than my colleagues’ work. They’re all doing wonderful things! But I’m just the only one actively promoting access to my research papers. If you tell people about your research, they look at it. Your research will get looked at more than papers which are not promoted via social media.
Some obvious points and conclusions. Don’t tweet things at midnight, you’ll get half the click throughs you get through the day when people are online. Don’t tweet important things on a Friday, especially not late – people do take weekends and you can see a clear drop off in downloads when the weekend rolls around and your paper falls a bit flat, as you sent it on its way on social media at the wrong time. The best time is between 11am and 5pm GMT, Monday to Thursday in a working week. I have the stats here somewhere to prove it. I wont write it up, though, as its pretty predictable (you would think! But somehow the message doesn’t get through to people that just putting it on twitter isnt enough, you have to time it right. The Discovery twitter account regularly posts an automated list of the really interesting things people have been looking at… at 10pm on a Friday night. Sheesh. I only know as I’m regularly sad enough to still be on twitter at that time, but I suspect if they tweeted the papers through the day during the working week… well, you guess what would happen?)
The paper that really flew – Digital Curiosities – has now been downloaded over a thousand times in the past year. It was the 16th most downloaded paper from our entire institutional repository in the final quarter of 2011, and the 3rd most downloaded paper in UCL’s entire Arts Faculty in the past year. It’s all relative really – what does this really mean? Well, I can tell you that this paper was the most downloaded paper in 2011 in LLC Journal, where it was published (and where it lives behind a paywall apart from being available free from Discovery). LLC is the most prestigious journal in the discipline I operate in, Digital Humanities. The entire download count for this paper from LLC itself, which made it top paper last year? 376 full text downloads. There have been almost 3 times that number of downloads from our institutional repository. What does this mean? What can we extrapolate from this? I think its fair to say: It’s a really good thing to make your work open access. More people will read it than if it is behind a paywall. Even if it is the most downloaded paper from a journal in your field, Open Access makes it even more accessed.
However. I might just have written a nice paper that caught people’s interest: there are, after all, no controls to this are there? No controls! How can we tell if papers would fly without this type of exposure? Well. Erm. I might not have have tweeted one or two papers to see the difference between tweeting and blogging about papers and not doing so. Take the LAIRAH (Log Analysis of Internet Resources in the Arts and Humanities) project, which I wrote about here. We actually published four papers from this research. I tweeted and promoted three of them actively. One I didnt mention to you. Here are the download counts. Guess which one I didnt circulate?
Library and information resources and users of digital resources in the humanities: 297 downloads
Documentation and the users of digital resources in the humanities: 209 downloads
If You Build It Will They Come? The LAIRAH Study: Quantifying the Use of Online Resources in the Arts and Humanities through Statistical Analysis of User Log Data.: 142 downloads
The Master Builders: LAIRAH Research on Good Practice in the Construction of Digital Humanities Projects: 12 downloads.
The papers that were tweeted and blogged had at least more than 11 times the number of downloads than their sibling paper which was left to its own devices in the institutional repository. QED, my friends. QED.
I cant know if the downloaded papers are read though, can I? The only way to do so is to enter the murky world of citation analysis. The trouble with this is the proof of the pudding will come to light in a few years time – if someone reads something of mine now and decides to cite it, its going to take 1 or even 2 years – or more – for it to appear in my citation list. So, I’ll be keeping an eye on things, not too seriously as we all know things like H index are problematic. Just for the record, at time of writing, I have 218 citations, according to Google scholar. My H index is 8, and my i10 index is 5, which is ok for a relatively young Humanities scholar (I’m still technically an Early Career Researcher for another year, as defined by the UK funding councils). Digital Curiosities only has 3 published citations to date. 3 published citations. Remember, it’s been downloaded over 1300 times, between LLC and our repository. Will this citation count grow? Will I be able to demonstrate, over the next few years, that retweeting leads to citation? Will I be able to tell how people came across my research – if they come across my research? We’ll see. Dont worry, I’ll blog it if I have anything to say on this.
I also know nothing about how many times my other papers are downloaded from the websites of published journals, or consulted in print in the Library. The latter, no-one can really say about – but the former? It seems strange to me that we write articles (without being paid) and we get them published by people who make a profit on them, then we don’t even know – usually – how many downloads they are getting from the journals themselves. The only reason I know about the LLC statistics is because I am good friends with the Editor. So, there are obvious advantages to being able to monitor my own downloads from my institutional repository. Its been a surprise to me to see what papers of mine are of interest to others. (Should that drive my research direction, though?)
The final point to make is that people don’t just follow me or read my blog to download my research papers. This has only been part of what I do online – I have more than 2000 followers on twitter now and it has taken me over 3 years of regular engagement – hanging out and chatting, pointing to interesting stuff, repointing to interesting stuff, asking questions, answering questions, getting stroppy, sending supportive comments, etc – to build up an “audience” (I’d actually call a lot of you friends!) If all I was doing was pumping out links to my published stuff would you still be reading this? Would you have read this? Would you keep reading? My blog is similar: sure, I’ve talked about my research, but I also post a variety of other content, some silly, some serious, as part of my academic work. I suspect this little experiment only worked as I already had a “digital presence” whatever that may mean. Thanks for putting up with me. All these numbers, these stats. Those clicks were made by real people. Thanks!
So that would be my conclusion, really. If you want people to find and read your research, build up a digital presence in your discipline, and use it to promote your work when you have something interesting to share. It’s pretty darn obvious, really:
If (social media interaction is often) then (Open access + social media = increased downloads).
What next? From now on, I will definitely post anything I publish straight into our institutional repository, and blog and tweet it straight away. After all, the time it takes to undertake research, and write research papers, and see them through to publication is large: the time is takes to blog or tweet about them is negligible. This has been a retrospective journey for me, through my past research, at a time when I came back from a period of leave. It’s been fun to get my act together like this – in general I needed to sort out my online systems at UCL, so it gave me some impetus to do so. But it has shown me that making your research available puts it out there – and as soon as I have something new to show you, you’ll be the first to know.
And here are a list of my personal top downloaded items from our repository, with download count since October, when I started this. Just for your eyes only, you understand.
| Terras, M (2009) Digital Curiosities: Resource Creation Via Amateur Digitisation. Literary and Linguistic Computing , 25 (4) 425 – 438. | 1014 |
| Ross, C and Terras, M and Warwick, C and Welsh, A (2011) Enabled backchannel: conference Twitter use by digital humanists. J DOC , 67 (2) 214 – 237. | 448 |
| Warwick, C. and Terras, M. and Galina, I. and Huntington, P. and Pappa, N. (2008) Library and information resources and users of digital resources in the humanities. Program: Electronic Library and Information Systems , 42 (1) pp. 5-27. | 297 |
| Terras, M (1999) A Virtual Tomb for Kelvingrove: Virtual Reality, Archaeology and Education. Internet Archaeology (7). | 253 |
| Warwick, C and Galina, I and Rimmer, J and Terras, M and Blandford, A and Gow, J and Buchanan, G (2009) Documentation and the users of digital resources in the humanities. J DOC , 65 (1) 33 – 57. | 209 |
| Terras, M and Van den Branden, R and Vanhoutte, E (2009) Teaching TEI: The Need for TEI by Example. Literary and Linguistic Computing , 24 (3) 297 – 306. | 194 |
| Terras, M (2010) Should we just send a copy? Digitisation, Use and Usefulness. Art Libraries Journal , 35 (1) | 193 |
| Warwick, C and Terras, M and Huntington, P and Pappa, N (2008) If You Build It Will They Come? The LAIRAH Study: Quantifying the Use of Online Resources in the Arts and Humanities through Statistical Analysis of User Log Data. LIT LINGUIST COMPUT , 23 (1) 85 – 102. | 142 |
| Warwick, C. and Fisher, C. and Terras, M. and Baker, M. and Clarke, A. and Fulford, M. and Grove, M. and O’Riordan, E. and Rains, M. (2009) iTrench: a study of user reactions to the use of information technology in field archaeology. LIT LINGUIST COMPUT , 24 (2) pp. 211-223. | 133 |

This is great and certainly I can report the same for me in terms of interest in my research.
But is there a causal gap here that needs to be filled. If your blog and twitter feeds were not so very popular would the 4x interest in research articles still be seen? Is it that you have built such a very strong social media presence that you have created a channel to market (so to speak) that privileges anything you post there?
If, for instance, you were posting a blog/twitter with 200 viewers per month would the growth factor in take up of downloads be the same 4x? If you had 20,000 followers would the growth take up remain x4 or would it also grow in a curve to match your following?
Is the causal relationship that you are “famous” and thus what you write has status and will be downloaded once people know it is out there?
I ask because in terms of what we want to learn form your example. Is it, get more followers then your research will be seen? Or is it, post your research and it will be seen more (however many folk follow you). These are slightly different strategies for the ordinary 'just got a couple of hundred followers' academic.
Fascinating and thought provoking blog as per usual. Thank you.
LikeLike
Great blog entry, Melissa. And, you're right, it is effective. Proof? I've just downloaded Digital Curiosities: Resource Creation Via Amateur Digitisation. Thank you, Rosvita
LikeLike
There is another reason to blog about research: Search engine optimisation and readability for non-academic audiences. While papers in academic journals may well be found through Google Scholar, having a journal article high on any topic-related regular Google search is rather seldom, while blogs tend to be ranked quite well on Google.
So making research findable both for academic and non-academic audiences needs publishing strategies that take into account how information and knowledge is researched today – and the way Google ranks results is definitely one aspect one cannot ignore.
Ron
LikeLike
Music to my ears:
“From now on, I will definitely post anything I publish straight into our institutional repository, and blog and tweet it straight away.”
Something I have been trying to convince scientists I work with to do for three years now!
http://ipasadelaide.wordpress.com/category/talkingpapers/
and
http://archive.org/search.php?query=talkingpapers
Keep up the sharing of your good work – look forward to your update on citations in 5 years time.
Fang – Mike Seyfang
p.s. I'm not a scientist, just a geek who cares
LikeLike
Great findings.
LikeLike